
没想到吧,我还会写技术文章。

前一阵子看了看自己的文章归档,发现我已经半年没有写过技术文章了,为了表示这个博主不是个只会写水文章的大水怪,我决定来写一篇硬核的技术文章,接招吧小伙子们。
然后我就开始选题,整理下来可以写(水)的有几个:一个是 Linux to Linux 云游戏平台的搭建过程,不过这个教程其实就是用各种别人的包然后改 Bug 的过程,写出来不够优雅,而且这东西搞出来就是为了玩游戏的,总感觉缺少一点专业的感觉。另一个是现在新版 QQ 机器人的创建,不过前一阵子 QQ 机器人遭到了巨大打击,现在也不是那么火了,我也懒得弄(不是),而且就算有估计肯定有很多人都写过了,咱不能重复造轮子,所以就放弃。
既然要写,就要写点其他人没写过的,什么东西写得人少呢,那当然是数学。

诶别走啊,虽然是数学,我会尽可能用口语化的方法来讲述核心的部分(不过还是要懂一些些高等数学的东西的,相信大家的高等数学 ABC、数学分析 ABC 都是 SSS 以上吧),让大家能够感觉到数学的魅力(确信)。耐心看完,你一定会有所收获。
那么下面我们开始。
正文
我写这篇文章主要 Follow 一篇 2001 年的 Paper:Orthogonal spline collocation methods for partial differential equations,这篇文章详细地介绍了 Orthogonal Spline Collocation Methods (OSC) 解多种情况下的偏微分方程(低阶、高阶、线性、非线形)。这篇文章我们先介绍最简单的一种情况,OSC 在单变量常微分方程中的原理和应用。至于高维的情况,如果大家感兴趣的话之后我也会尝试写一写,不过篇幅估计就不会像这一篇一样这么短了。
首先,大家应该都比较熟悉样条插值法了,这是数值分析中的基础核心方法之一,如果不了解的话,可以在 Wiki (https://zh.wikipedia.org/wiki/样条插值) 上花几分钟时间快速浏览一下,其原理很简单,就是用多个分段多项式或其他种类的基函数“拼接”来表示一个高维或者部分未知的函数。最简单的情况,我们把点和点直接连接起来其实就是一种线性函数的样条插值,即
$$S_i(x)=y_i+\frac{y_{i+1}-y_i}{x_{i+1}-x_i}(x-x_i)$$
样条插值法和我们要介绍的 OSC 原理相似,只有一点使用上的差别:样条插值方法需要具体知道函数在每个插值点的值,而 OSC 方法并不需要,我们只需要知道原方程即可。这也是 OSC 这个方法炫酷的地方,使得它不像是一个数值方法,而更像一个 Solver.
下面我们来具体介绍 OSC 的流程。
Step 1. 选取 Partition Points 和 Collocation Points
既然我们打算分段拟合,那么首先我们要把函数的 Domain 划分一下。Partition points 的选择没有太多的约束,如果没有特殊的精度要求可以直接选择均匀分布。选好的 Partition points 我们记为
$x_i, i=0, \cdots, N, x_0 = 0, x_N = 1$
一共是 $N + 1$ 个。
下面我们选取 Collocation points,其实 Collocation points 的选择也比较自由,只是相比 Partition points,Collocation points 的选择对结果的影响相对大一些。原文章中选取的方法是遵循 Gauss-Legendre Quadrature Rule,这样选取的 Collocation points 直观理解上会更容易控制和反映真实解。好消息是基于 Gauss-Legendre Quadrature Rule 选取值我们有表可以查,不用自己算,而且在实现过程中 Numpy 也提供相应的函数直接获取我们需要的值。
Collocation points 选取的数量比较讲究,这取决于我们准备用几维的函数来拟合解,如果我们用 $r$ 维的函数来拟合,那么在每个 Partition 中我们需要选择 $r-1$ 个 Collocation points。至于为什么是这个数值,我们在下面的推导中会讲解。我们把选好的 Collocation points 标为 $\xi_i, i=1, \cdots, N\times (r-1)$.
到此为止我们选好了 Partition points 和 Collocation points,这里我来举个具体的例子方便理解。比如我们准备用 $3$ 个分段的函数来拟合函数,我们就需要 $3 + 1 = 4$ 个 Partition points,然后我们想要用三维的函数来拟合,那么每个 Partition 中间我们要找 $3 - 1 = 2$ 个 Collocation points,即此时 $N=4, r=3$,选好的 Partition points 和 Collocation points 画出来就会是这个样子。
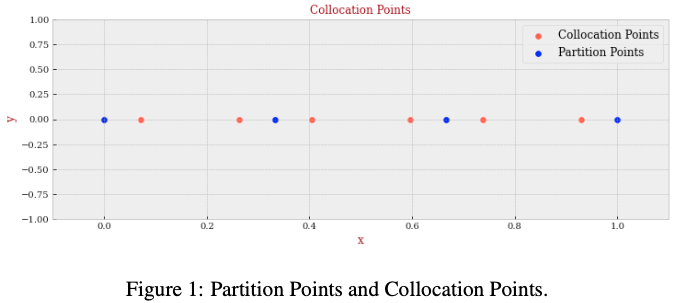
Step 2. 将原方程问题转换为线性代数问题
这一步就是 OSC 方法的核心了,也是这个算法最强大的地方。为了方便大家理解,我决定全程用例子来讲,因为我读原论文的时候发现都是一般化的解释,花了好久时间才搞懂,不如一个例子来的快。我们接着上面的设定来,现在我们有 3 个 Partition,在每个 Partition 上面有一个函数,我们记为
$$h_1(x) = a_{0, 0} + a_{0, 1}x + a_{0, 2}x^2, x\in[x_0, x_1] $$ $$h_2(x) = a_{1, 0} + a_{1, 1}x + a_{1, 2}x^2, x\in[x_1, x_2] $$ $$h_3(x) = a_{2, 0} + a_{2, 1}x + a_{2, 2}x^2, x\in[x_2, x_3] $$
现在让我们考虑,如果我们把这 3 个函数放在一起当作方程解的拟合,我们需要做到什么?首先,最基本的,这 3 个函数至少是 $C^1$ 连续的。为了达到 $C^1$ 连续的要求,函数和函数之间在相连的地方需要值相等且一阶导数值相等。比如 $h_1$ 和 $h_2$ 在 $x_1$ 的地方必需要有同样的值而且导数相等,所以我们可以因此列出两个方程
$$a_{0, 0} + a_{0, 1}x_1 + a_{0, 2}x_1^2 = a_{1, 0} + a_{1, 1}x_1 + a_{1, 2}x_1^2$$ $$0 + a_{0, 1} + 2a_{0, 2}x_1 = 0 + a_{1, 1} + 2a_{1, 2}x_1$$
让我们看看我们针对连续这个约束条件一共创建了几个方程,我们有 $N+1$ 个 Partition points 的时候我们会对 $N-1$ 个 Partition points 考虑连续方程(除去了边界点),在每个 Partition points 我们会创建 2 个方程,那么我们一共有 $(N-1) \times 2 = 4$ 个方程。
如果你还记得高等代数中的自由度概念的话,下面这部分会很容易理解。我们一开始有 3 个函数,每个函数有 4 个 Parameters,那么我们一共有 12 个 Parameters。如果没有约束的话现在自由度是 12.
考虑到连续可以帮我们创建 4 个方程,那么这些参数的自由度下降到 8,再加上左右边界的两个约束,现在参数的自由度下降到了 6. 那么这时候我们发现我们正好有 6 个 Collocation points,也就是现在的 Collocation points 可以刚好确定我们的所有参数。
如果用一般形式来计算自由度,将会是这样
$$N\times (r+1)=2+(N-1)\times 2+N\times(r-1)$$
讨论结束之后我们来用实际的例子来验证一下。假设我们现在的问题是一个一维常微分方程
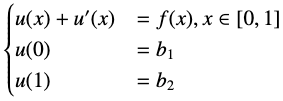
那么我们带入 Collocation points 的时候会得到这样的方程
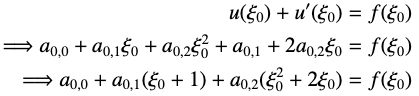
把所有方程放在一起,我们就可以发现我们得到了一个线性方程组,解这个线性方程组我们就可以得到我们的拟合函数了。
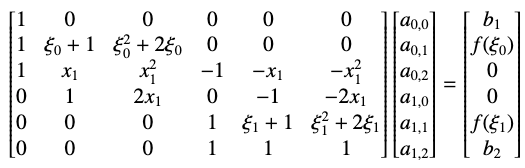
所以到此为止我们应该已经可以见识到了 OSC 方法的强大之处,只需要给我们一个常微分方程的表达式,我们不需要计算任何具体函数解的值,我们就可以将这个方程转化为一个线性方程组的求解问题,而且据原论文证明,这个方法对于三维以下的方程组都是理论收敛的,也就是保证有解。这么高质量的方法实在是非常帅气。
Step 3. 解线性方程组
你可能会好奇其实这个方法的介绍在 Step 2. 就可以宣告结束了,毕竟我们都得到拟合函数了。但是实际上解通过 Step 2 得到的线性方程组并不是那么容易,我们在 Step 2. 中的例子非常的 Toy,在实际中 Partition points 的数量和维度都可能会高不少,主要是 Partition points,对于复杂的问题我们可能会选择十几个到几十个 Partition points,容易想象到这个线性方程组会很 Large Scale。
但是又有个好消息,这个线性方程组不是一般的线性方程组,而是有规律的。如果你仔细观察 Step 2. 得到的线性方程组矩阵,会大概能猜到这是一个”区块对角“矩阵。针对这样的矩阵我们其实有很多高效的特殊办法去解,相比直接动手去解方程组快多了。
至于这样的特殊解法,可以参考原文章的 Refer。内容有点超出我们这篇文章的范围,所以就不讲太多了(我懒,或者说可以留着水下一篇文章)。在实际中可以直接调用包来快速解这样的线性方程组。
另一个想要在这里讨论的是这个算法的复杂度,原 Paper 给出的复杂度是 $O(N^2)$ 或者 $O(N^2\mathrm{log}N)$,整体上来看是一个非常不错的。但是如果我们考虑二维或者高维的情况,那么就复杂太多了,所以还是需要注意。
结果
好的,到现在为止我们的模型已经介绍完了,那么我们来看一些简单的结果吧。这样可以方便大家形像地理解这个方法。
和前面我们讲解中选择的 N 和 r 值一样,这里我们依然使用 N=3, r=3, 所要拟合的方程是
$$u’’ + u’ + u = 10x^3 + 14x^2 - 34x - 26$$
$$u(0)=0$$
$$u(1)=0$$
一顿操作猛如虎,我们的拟合结果画出来是这样的
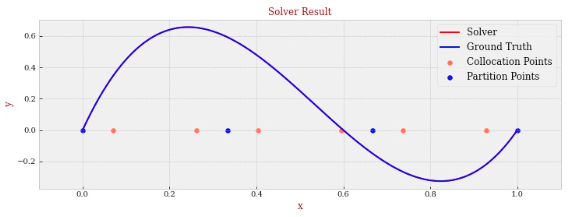
我们可以看到对于原本真实解就是三次的情况下,我们的 Simulator 可以给出几乎一模一样的结果,即它直接找到了真实解。
对于高维的真实解,通过这个方法可以得到大致的模拟,目前仍存在的一个问题是低次对于高次的拟合准确度还有待提升,比如下面这张图就是用三次的解来尝试模拟四次的真实解。虽然不是那么完美,但是至少寻找解的方向是对的。

好消息是这个方法对于非线性解是有效的,比如下面这张图就是用三次解来模拟三角函数基的解,也几乎可以达到完美的匹配程度。我们也认为这是这个方法最 Powerful 的地方。
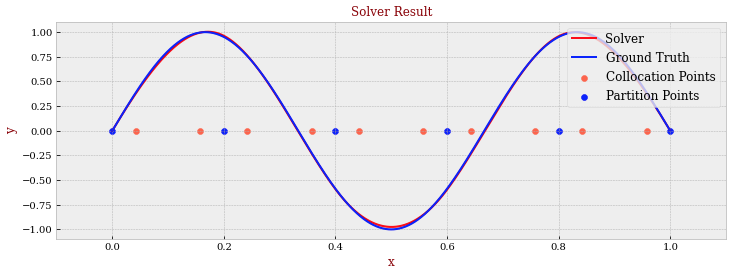
这里是我们主要给出的三个例子,这个方法可以应用于任何一维常微分方程上面来测试结果,所以如果你对这个方法感兴趣可以亲自试试。我在 GitHub 上提供了一维 OSC 方法的代码,据我了解似乎之前并没有人尝试用过这个方法,姑且算是我的 Contribution 了,欢迎 Refer, Frok 和 Star.

结尾
我们这里讨论的是一维的 OSC 方法,虽然展现了其一些特性和亮点,但是实际上只体现了 OSC 方法很小一部分的能力,更强大的能力在于高维方程的拟合上面。当然,高维的问题必然带来指数级的复杂度上升,这也是我没有一口气把二维 OSC 的讨论一并写在这里的原因。
如果你对二维 OSC 方法感兴趣的话可以去读一读原论文的第三章,相信你一定会被这个方法的巧妙所吸引的。除此之外,据我搜索在 GitHub 上面还没有人发布二维 OSC 方法的代码。我已经实现了这个方法,只是目前我还要先用于我的 Research 上面,所以暂时先不发布。等我的 Research 告一段落之后我会尝试写一篇更加丰富、更加硬核的针对二维甚至是高维的 OSC 方法的解读。
网站的硬核程度上升了!